 ADAC.
ADAC.
Abstract
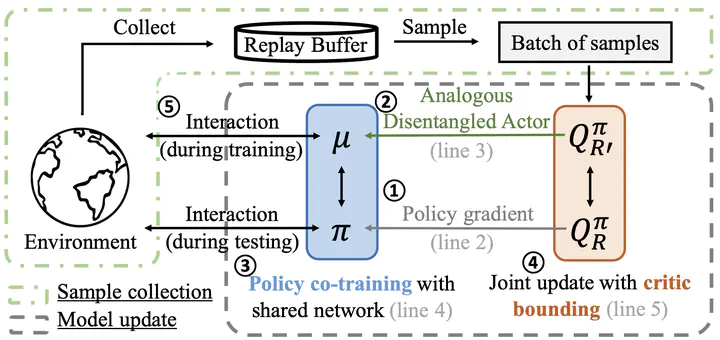
Off-policy reinforcement learning (RL) is concerned with learning a rewarding policy by executing another policy that gathers sam- ples of experience. While the former policy (i.e. target policy) is rewarding but in-expressive (in most cases, deterministic), doing well in the latter task, in contrast, requires an expressive policy (i.e. behavior policy) that offers guided and effective exploration. Contrary to most methods that make a trade-off between optimality and expressiveness, disentangled frameworks explicitly decouple the two objectives, which each is dealt with by a distinct separate policy. Although being able to freely design and optimize the two policies with respect to their own objectives, naively disentangling them can lead to inefficient learning or stability issues. To mitigate this problem, our proposed method Analogous Disentangled Actor-Critic (ADAC) designs analogous pairs of actors and critics. Specifically, ADAC leverages a key property about Stein variational gradient descent (SVGD) to constraint the expressive energy-based behavior policy with respect to the target one for effective exploration. Additionally, an analogous critic pair is intro- duced to incorporate intrinsic rewards in a principled manner, with theoretical guarantees on the overall learning stability and effectiveness. We empirically evaluate environment-reward-only ADAC on 14 continuous-control tasks and report the state-of-the-art on 10 of them. We further demonstrate ADAC, when paired with intrinsic rewards, outperform alternatives in exploration-challenging tasks.